Discover how Pinecone in Python revolutionises data management with its high-performance vector database (pinecone db), ideal for AI applications, similarity search, and recommendation systems. Embrace the power of efficient and scalable vector storage with Pinecone in Python, the leading choice for AI/ML developers.
Pinecone in Python is a vector database. It is especially useful for handling and managing high-dimensional vector embeddings in AI applications in the form of an Index (Serverless Index).
Pinecone provides an efficient solution for tasks such as similarity search, recommendation systems, and anomaly detection by allowing fast and accurate retrieval of nearest neighbour in vector space.
Need for Vector Database: Pinecone in Python
Vectors play a critical role in numerous machine learning and artificial intelligence applications, particularly in areas like natural language processing (NLP) and image recognition. These mathematical constructs allow for the representation of data in a numerical format that machine learning models can process efficiently. In the context of NLP, vectors often represent words or phrases as embeddings, capturing semantic relationships and enabling tasks such as text classification, sentiment analysis, and language translation. Similarly, in image recognition, vectors can represent images or features within images, allowing models to perform tasks like object detection and image classification with high accuracy.
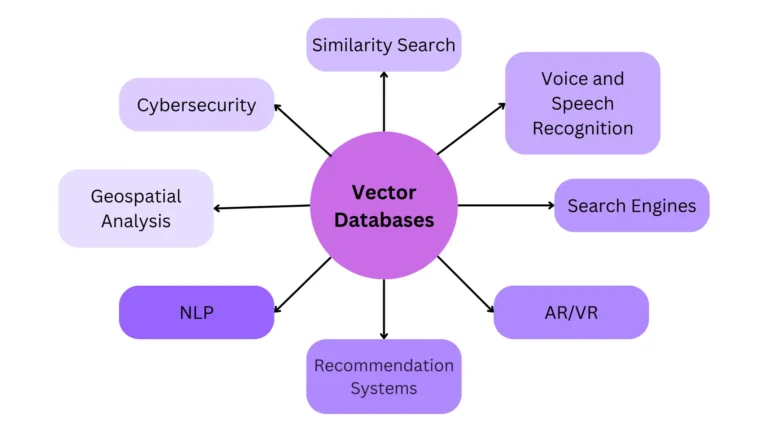
Vector databases are specialized storage systems designed to handle the unique requirements of vector data. They store embeddings generated by machine learning models, enabling quick and efficient retrieval of relevant information. This capability is crucial for applications that require real-time data analysis and decision-making, such as recommendation systems, anomaly detection, and search engines. By facilitating rapid access to high-dimensional vector data, vector databases empower organizations to harness the full potential of machine learning models, driving innovation and improving outcomes across various domains.
Terms related to Pinecone in Python
A. Vectors Vs Embeddings: Difference between Vectors and Embeddings
Vectors and embedding are one of the basic concepts in vector databases, they both are related but distinct. In the context of database and machine learning both the vector and embedding are used interchangeably but they differ significantly. Below is the comparison of both the terms:
Vector
- General purpose representation of data points. Vectors are originated from various data types and used for broad computational purposes.
- Vector represents simple and complex data but does not carry contextual or relation information by default.
- Used in a variety of mathematical and computational applications (not limited to similarity searches).
- Superset (i.e., vectors are broader category of data representation), not all vectors are embeddings.
Embedding
- These are specially designed to encode complex data into a format that holds relationships between data. These are created by machine learning models.
- Embeddings are inherently context-aware and rich in carrying semantic information of the data.
- Used in machine learning applications in understanding and utilizing semantic relationships.
- Subset (i.e., embeddings are specialized forms of vector), all embeddings are vectors.
B. Vector Database
A vector database is a special type of database that is designed to store, index, and query vector embedding data. Embeddings are high-dimensional numerical representations used to encode complex information such as images, text, and audio.
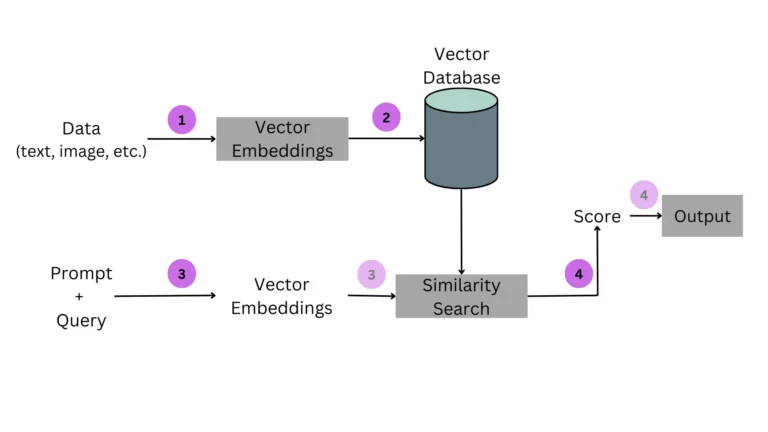
The main idea behind vector databases is to facilitate rapid and similar searches among the vectors. Instead of traditional databases, which query on the exact matches, a vector database allow search based on the most similar item based on their vector representation (embedding).
> Key Features:
- Ability to handle high dimensional data.
- Fast nearest neighbour searches.
- Scalability (capacity to scale with large volumes of data).
- Compatible with modern data-driven applications.
C. Vector Search
The technique to find similar items based on their vector representation (embeddings).
> Working:
- Convert the item (text, image, etc) to high dimensional vector representation (Vectors carry essential features of the item).
- Store embeddings/ vectors in the vector databases like Pinecone in Python.
- When a user raises a query, the query is converted into a vector and a search (matching) is initialized.
- Similarity scores are generated based on the similarity function used and the most relevant item(s) is returned.
> Advantage:
- Less expensive (in terms of computational resources)
- More effective
- Accurate retrieval
- Easy to integrate
- Cloud-native (easy to integrate into cloud)
- Low latency (less time delay between query and response)
D. Pinecone Client
Pinecone client is the interface that enables users to interact with the Pinecone db in Python. It helps in connecting and easily managing the Pinecone instance.
> Types of connection:
There are 2 possible ways to create a Pinecone client in Python.
- Default (HTTP client):
Installed from PyPI as pinecone-client with minimal dependencies and uses HTTP request to interact with the client.
pip3 install pinecone-client
2. GRPC client:
Installed with additional dependencies using pinecone-client[grpc], it provides better performance for large projects and is performance optimized client.
pip3 install pinecone-client[grpc]
E. Serverless Index
The Serverless Index is the highest level of organizational unit of data where you define the dimension of the vector to be stored and the similarity metric used to perform a similarity search. Code to create a serverless index.
> Advantages:
- Automatically scaled (No need to manage or compute storage resources)
- Limitless scaling
- Guarantee of high availability
- Pay-as-you go
Basic Architecture of Pinecone Database
The highest level of data storage unit in the Pinecone database is an Index (also known as serverless index).
Each Index is divided into several Namespaces which contain multiple Records.
Each record in the database is made up of 2 fields, i.e.,
id (unique identifier) and
values (the vector/ embedding data which also refer to the dimension of the index).

Initial Setup: Importing Modules and Creating Pinecone Instance
To use the Pinecone database in any Python project, it is essential to import the dependencies and create an initial Pinecone instance. Below is the three-step process to do so.
Step 1. Importing Pinecone client (let say grpc client): It is a part of Python SDK and is essential to interact with pinecone service.
from pinecone.grpc import PineconeGRPC as Pinecone
Step 2. Importing Serverless spec class: Used to configure the specifications for Pinecone.
from pinecone import ServerlessSpec
Step 3. Creating Pinecone client instance: To connect to your pinecone account and to be able to create the database.
pc = Pinecone(api_key = 'your_api_key_here')
Creating Your First Index: Serverless Index
# Name of the index
index_name = 'your_db_name'
#Checking if the index with your_db_name already exist
if index_name not in pc.list_indexes().names():
pc.create_index(
name = index_name,
dimension = 2,
metric = 'cosine',
spec = ServerlessSpec (
cloud = 'aws',
region = 'us-east-1'
)
)
else:
print(f"Database with {index_name} name already exist")
In the above code change the value of the name, dimension, metric and spec according to your project requirements. The default value for cloud and region is ‘aws’ and ‘us-east-1’ respectively.
To insert the value into the index Upsert operation is used and to check the value of index describe_index_stats is used in Pinecone.
Updating/ Inserting Index: Upsert Vector
Upsert (Update/ Insert) is used to update or insert the vector within a namespace as records.
# Index as above code
index = index_name
#Inserting value in the created index index_name under namespace 1
index.upsert(
vectors = [
{'id':'vec1', 'values':[0.1, 1.4]},
{'id':'vec2', 'values':[2.4, 1.0]},
{'id':'vec3', 'values':[0.6, 3.1]}
],
namespace = 'ns1'
)
#Inserting value in the created index index_name under namespace 2
index.upsert(
vectors = [
{'id':'ve1', 'values':[4.4, 1.1]},
{'id':'ve2', 'values':[2.0, 3.0]}
],
namespace = 'ns2'
)
The vectors with id ‘vec1’, ‘vec2’, ‘vec3’ are the 2-dimensional (determined by looking at the values field, i.e., the values field contains 2 data points 0.1 and 1.4 for vec1 and similar for vec2 and vec3) record 1, 2 and 3 respectively inside the namespace ‘ns1’, which combined create the vector with name ‘index_name’.
Check the Index: Describing the Index
print(index.describe_index_stats())
# Output
{'dimension': 2,
'index_fullness': 0.0,
'namespace': {
'ns1': {'vector_count': 3},
'ns2': {'vector_count': 2}
},
'total_vector_count': 5
}
It is used to check if the index is created successfully of not.
Similarity Check
result = index.query(
namespace = 'ns1',
vector = [1.0, 1.5],
top_k = 3,
include_value = True
)
Query the namespaces for most similar vectors. Here, the vector is the new vector for which the search is being performed and top_k is the value of top k (here 3) most similar vectors to be returned, and include_value implies if the values field is to be returned or not.
# Sample Output
{'matches': [
{'id': 'vec3', 'score': 1.0, 'values': [0.6, 3.1]},
{'id': 'vec2', 'score': 0.8, 'values': [2.4, 1.0]},
{'id': 'vec1', 'score': 0.6, 'values': [0.1, 1.4]}
],
'namespace': 'ns1',
'usage': {'read_units': 6}
}
Cleanup: Deleting the Vector pinecone in python
To delete the index permanently.
pc.delete_index(index_name)
>> Key Takeaways <<
- Vector Databases Overview:
- Pinecone in Python is a vector database designed for handling high-dimensional vector embeddings.
- It supports AI applications by providing serverless indexing capabilities
- Specialized for managing vector data and embeddings.
- Facilitate rapid data retrieval, essential for real-time analysis and decision-making.
- Support various applications like search engines and anomaly detection.
- Applications of Pinecone
- Efficient for tasks like similarity search, recommendation systems, and anomaly detection.
- Enables fast and accurate retrieval of nearest neighbours in vector space.
- Vectors vs. Embeddings
- Vectors: General-purpose data representations.
- Vectors represent data numerically for machine learning, crucial in NLP and image recognition.
- Used to encode words, images, and other data for tasks like text classification and object detection.
- Embeddings: Special vectors capturing data relationships, created by machine learning models for tasks like language translation and image classification.
- Click here to know more.
- Vectors: General-purpose data representations.
Pinecone Client:
- Interface for interacting with Pinecone in Python.
- Supports two types of connections: HTTP client for general use and GRPC client for optimized performance.
Serverless Index:
- Highest level of data organization in Pinecone, supporting automatic scaling and high availability.
- Enables definition of vector dimensions and similarity metrics for efficient indexing and querying.
- Click here to know more.
Pinecone Database Architecture:
- Organized into indexes, namespaces, and records.
- Records consist of unique identifiers and vector data, facilitating efficient data management and retrieval.
- Click here to know more.
Steps for Using Pinecone:
- Import necessary modules and create a Pinecone instance.
- Create and manage indexes, insert vectors, and perform similarity searches.
- Use operations like upsert for updating/inserting data and describe_index_stats for checking index status.
- Click here to know more.
Similarity Check Example:
- Demonstrates querying a namespace for the most similar vectors to a given query vector.
- Provides sample output with matching vectors and similarity scores.
Cleanup Process:
- Instructions for permanently deleting indexes from the Pinecone database.
References:
1. pinecone.io
Explore more content on our website.
Click here to explore Data Science content.

